![]()
Jun-2026 Free Databricks Databricks-Certified-Professional-Data-Engineer Exam Question Practice Exams
Ace Databricks-Certified-Professional-Data-Engineer Certification with 204 Actual Questions
NEW QUESTION # 104
The DevOps team has configured a production workload as a collection of notebooks scheduled to run daily using the Jobs Ul. A new data engineering hire is onboarding to the team and has requested access to one of these notebooks to review the production logic.
What are the maximum notebook permissions that can be granted to the user without allowing accidental changes to production code or data?
- A. Can edit
- B. Can run
- C. Can Read
- D. Can manage
Answer: C
Explanation:
Granting a user 'Can Read' permissions on a notebook within Databricks allows them to view the notebook's content without the ability to execute or edit it. This level of permission ensures that the new team member can review the production logic for learning or auditing purposes without the risk of altering the notebook's code or affecting production data and workflows. This approach aligns with best practices for maintaining security and integrity in production environments, where strict access controls are essential to prevent unintended modifications.
Reference: Databricks documentation on access control and permissions for notebooks within the workspace (https://docs.databricks.com/security/access-control/workspace-acl.html).
NEW QUESTION # 105
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFramedf. The pipeline needs to calculate the average humidity and average temperature for each non- overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFramedfhas the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:
Choose the response that correctly fills in the blank within the code block to complete this task.
- A. lag("event_time", "10 minutes").alias("time")
- B. window("event_time", "5 minutes").alias("time")
- C. "event_time"
- D. to_interval("event_time", "5 minutes").alias("time")
- E. window("event_time", "10 minutes").alias("time")
Answer: B
Explanation:
This is the correct answer because the window function is used to group streaming data by time intervals. The window function takes two arguments: a time column and a window duration. The window duration specifies how long each window is, and must be a multiple of 1 second. In this case, the window duration is "5 minutes", which means each window will cover a non-overlapping five-minute interval. The window function also returns a struct column with two fields: start and end, which represent the start and end time of each window. The alias function is used to rename the struct column as "time". Verified References: [Databricks Certified Data Engineer Professional], under "Structured Streaming" section; Databricks Documentation, under "WINDOW" section.https://www.databricks.com/blog/2017/05/08/event-time-aggregation- watermarking-apache-sparks-structured-streaming.html
NEW QUESTION # 106
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema "customer_id LONG, predictions DOUBLE, date DATE".
The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
- A.

- B. preds.write.format("delta").save("/preds/churn_preds")
- C. preds.write.mode("append").saveAsTable("churn_preds")
- D.

- E.

Answer: C
NEW QUESTION # 107
Which statement describes integration testing?
- A. Requires an automated testing framework
- B. Validates an application use case
- C. Validates behavior of individual elements of your application
- D. Requires manual intervention
- E. Validates interactions between subsystems of your application
Answer: E
Explanation:
Explanation
This is the correct answer because it describes integration testing. Integration testing is a type of testing that validates interactions between subsystems of your application, such as modules, components, or services.
Integration testing ensures that the subsystems work together as expected and produce the correct outputs or results. Integration testing can be done at different levels of granularity, such as component integration testing, system integration testing, or end-to-end testing. Integration testing can help detect errors or bugs that may not be found by unit testing, which only validates behavior of individual elements of your application. Verified References: [Databricks Certified Data Engineer Professional], under "Testing" section; Databricks Documentation, under "Integration testing" section.
NEW QUESTION # 108
All records from an Apache Kafka producer are being ingested into a single Delta Lake table with the following schema:
key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG There are 5 unique topics being ingested. Only the "registration" topic contains Personal Identifiable Information (PII). The company wishes to restrict access to PII. The company also wishes to only retain records containing PII in this table for 14 days after initial ingestion. However, for non-PII information, it would like to retain these records indefinitely.
Which of the following solutions meets the requirements?
- A. Data should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
- B. Data should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries.
- C. Because the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
- D. All data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
- E. Separate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
Answer: B
Explanation:
Partitioning the data by the topic field allows the company to apply different access control policies and retention policies for different topics. For example, the company can use the Table Access Control feature to grant or revoke permissions to the registration topic based on user roles or groups. The company can also use the DELETE command to remove records from the registration topic that are older than 14 days, while keeping the records from other topics indefinitely. Partitioning by the topic field also improves the performance of queries that filter by the topic field, as they can skip reading irrelevant partitions. References:
* Table Access Control: https://docs.databricks.com/security/access-control/table-acls/index.html
* DELETE: https://docs.databricks.com/delta/delta-update.html#delete-from-a-table
NEW QUESTION # 109
A new data engineer notices that a critical field was omitted from an application that writes its Kafka source to Delta Lake. This happened even though the critical field was in the Kafka source. That field was further missing from data written to dependent, long-term storage. The retention threshold on the Kafka service is seven days. The pipeline has been in production for three months.
Which describes how Delta Lake can help to avoid data loss of this nature in the future?
- A. Ingestine all raw data and metadata from Kafka to a bronze Delta table creates a permanent, replayable history of the data state.
- B. Delta Lake schema evolution can retroactively calculate the correct value for newly added fields, as long as the data was in the original source.
- C. Data can never be permanently dropped or deleted from Delta Lake, so data loss is not possible under any circumstance.
- D. The Delta log and Structured Streaming checkpoints record the full history of the Kafka producer.
- E. Delta Lake automatically checks that all fields present in the source data are included in the ingestion layer.
Answer: A
Explanation:
Explanation
This is the correct answer because it describes how Delta Lake can help to avoid data loss of this nature in the future. By ingesting all raw data and metadata from Kafka to a bronze Delta table, Delta Lake creates a permanent, replayable history of the data state that can be used for recovery or reprocessing in case of errors or omissions in downstream applications or pipelines. Delta Lake also supports schema evolution, which allows adding new columns to existing tables without affecting existing queries or pipelines. Therefore, if a critical field was omitted from an application that writes its Kafka source to Delta Lake, it can be easily added later and the data can be reprocessed from the bronze table without losing any information. Verified References:
[Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Delta Lake core features" section.
NEW QUESTION # 110
A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG
post_text STRING
post_id STRING
longitude FLOAT
latitude FLOAT
post_time TIMESTAMP
date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
- A. post_time
- B. user_id
- C. date
- D. post_id
Answer: C
Explanation:
Partitioning a Delta Lake table is a strategy used to improve query performance by dividing the table into distinct segments based on the values of a specific column. This approach allows queries to scan only the relevant partitions, thereby reducing the amount of data read and enhancing performance.
Considerations for Choosing a Partition Column:
Cardinality: Columns with high cardinality (i.e., a large number of unique values) are generally poor choices for partitioning. High cardinality can lead to a large number of small partitions, which can degrade performance.
Query Patterns: The partition column should align with common query filters. If queries frequently filter data based on a particular column, partitioning by that column can be beneficial.
Partition Size: Each partition should ideally contain at least 1 GB of data. This ensures that partitions are neither too small (leading to too many partitions) nor too large (negating the benefits of partitioning).
Evaluation of Columns:
date:
Cardinality: Typically low, especially if data spans over days, months, or years.
Query Patterns: Many analytical queries filter data based on date ranges.
Partition Size: Likely to meet the 1 GB threshold per partition, depending on data volume.
user_id:
Cardinality: High, as each user has a unique ID.
Query Patterns: While some queries might filter by user_id, the high cardinality makes it unsuitable for partitioning.
Partition Size: Partitions could be too small, leading to inefficiencies.
post_id:
Cardinality: Extremely high, with each post having a unique ID.
Query Patterns: Unlikely to be used for filtering large datasets.
Partition Size: Each partition would be very small, resulting in a large number of partitions.
post_time:
Cardinality: High, especially if it includes exact timestamps.
Query Patterns: Queries might filter by time, but the high cardinality poses challenges.
Partition Size: Similar to user_id, partitions could be too small.
Conclusion:
Given the considerations, the date column is the most suitable candidate for partitioning. It has low cardinality, aligns with common query patterns, and is likely to result in appropriately sized partitions.
Reference:
Delta Lake Best Practices
Partitioning in Delta Lake
NEW QUESTION # 111
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on Task A.
If task A fails during a scheduled run, which statement describes the results of this run?
- A. Unless all tasks complete successfully, no changes will be committed to the Lakehouse; because task A failed, all commits will be rolled back automatically.
- B. Because all tasks are managed as a dependency graph, no changes will be committed to the Lakehouse until all tasks have successfully been completed.
- C. Tasks B and C will attempt to run as configured; any changes made in task A will be rolled back due to task failure.
- D. Tasks B and C will be skipped; task A will not commit any changes because of stage failure.
- E. Tasks B and C will be skipped; some logic expressed in task A may have been committed before task failure.
Answer: E
Explanation:
Explanation
When a Databricks job runs multiple tasks with dependencies, the tasks are executed in a dependency graph. If a task fails, the downstream tasks that depend on it are skipped and marked as Upstream failed. However, the failed task may have already committed some changes to the Lakehouse before the failure occurred, and those changes are not rolled back automatically. Therefore, the job run may result in a partial update of the Lakehouse. To avoid this, you can use the transactional writes feature of Delta Lake to ensure that the changes are only committed when the entire job run succeeds. Alternatively, you can use the Run if condition to configure tasks to run even when some or all of their dependencies have failed, allowing your job to recover from failures and continue running. References:
transactional writes: https://docs.databricks.com/delta/delta-intro.html#transactional-writes Run if: https://docs.databricks.com/en/workflows/jobs/conditional-tasks.html
NEW QUESTION # 112
A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE This table is partitioned by the date column. A query is run with the following filter:
longitude < 20 & longitude > -20
Which statement describes how data will be filtered?
- A. Statistics in the Delta Log will be used to identify data files that might include records in the filtered range.
- B. No file skipping will occur because the optimizer does not know the relationship between the partition column and the longitude.
- C. The Delta Engine will scan the parquet file footers to identify each row that meets the filter criteria.
- D. Statistics in the Delta Log will be used to identify partitions that might Include files in the filtered range.
- E. The Delta Engine will use row-level statistics in the transaction log to identify the flies that meet the filter criteria.
Answer: A
Explanation:
This is the correct answer because it describes how data will be filtered when a query is run with the following filter: longitude < 20 & longitude > -20. The query is run on a Delta Lake table that has the following schema: user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE. This table is partitioned by the date column. When a query is run on a partitioned Delta Lake table, Delta Lake uses statistics in the Delta Log to identify data files that might include records in the filtered range. The statistics include information such as min and max values for each column in each data file. By using these statistics, Delta Lake can skip reading data files that do not match the filter condition, which can improve query performance and reduce I/O costs. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Data skipping" section.
NEW QUESTION # 113
A data engineer needs to provide access to a group named manufacturing-team. The team needs privileges to create tables in the quality schema.
Which set of SQL commands will grant a group named manufacturing-team to create tables in a schema named production with the parent catalog named manufacturing with the least privileges?
- A. GRANT CREATE TABLE ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT CREATE SCHEMA ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT CREATE CATALOG ON CATALOG manufacturing TO manufacturing-team;
- B. GRANT USE TABLE ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT USE SCHEMA ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT USE CATALOG ON CATALOG manufacturing TO manufacturing-team;
- C. GRANT CREATE TABLE ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT CREATE SCHEMA ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT USE CATALOG ON CATALOG manufacturing TO manufacturing-team;
- D. GRANT CREATE TABLE ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT USE SCHEMA ON SCHEMA manufacturing.quality TO manufacturing-team; GRANT USE CATALOG ON CATALOG manufacturing TO manufacturing-team;
Answer: D
Explanation:
To create a table within a schema, a principal must have CREATE TABLE on the schema, USE SCHEMA on that schema, and USE CATALOG on the parent catalog. This combination ensures the group has just enough privileges to create objects in that schema without excessive permissions like CREATE SCHEMA or CREATE CATALOG.
Reference Source: Databricks Unity Catalog Privilege Model - "Privileges Required to Create a Table."
NEW QUESTION # 114
Which is a key benefit of an end-to-end test?
- A. It makes it easier to automate your test suite
- B. It provides testing coverage for all code paths and branches.
- C. It pinpoint errors in the building blocks of your application.
- D. It closely simulates real world usage of your application.
Answer: D
Explanation:
End-to-end testing is a methodology used to test whether the flow of an application, from start to finish, behaves as expected. The key benefit of an end-to-end test is that it closely simulates real-world, user behavior, ensuring that the system as a whole operates correctly.
Reference:
Software Testing: End-to-End Testing
NEW QUESTION # 115
At the end of the inventory process, a file gets uploaded to the cloud object storage, you are asked to build a process to ingest data which of the following method can be used to ingest the data in-crementally, schema of the file is expected to change overtime ingestion process should be able to handle these changes automatically.
Below is the auto loader to command to load the data, fill in the blanks for successful execution of below code.
1.spark.readStream
2..format("cloudfiles")
3..option("_______","csv)
4..option("_______", 'dbfs:/location/checkpoint/')
5..load(data_source)
6..writeStream
7..option("_______",' dbfs:/location/checkpoint/')
8..option("_______", "true")
9..table(table_name))
- A. cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, append
- B. cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, overwrite
- C. cloudfiles.format, checkpointlocation, cloudfiles.schemalocation, overwrite
- D. format, checkpointlocation, schemalocation, overwrite
- E. cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, mergeSchema
Answer: E
Explanation:
Explanation
The answer is cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, mergeSchema.
Here is the end to end syntax of streaming ELT, below link contains complete options Auto Loader options | Databricks on AWS
1.spark.readStream
2..format("cloudfiles") # Returns a stream data source, reads data as it arrives based on the trigger.
3..option("cloudfiles.format","csv") # Format of the incoming files
4..option("cloudfiles.schemalocation", "dbfs:/location/checkpoint/") The location to store the inferred schema and subsequent changes
5..load(data_source)
6..writeStream
7..option("checkpointlocation","dbfs:/location/checkpoint/") # The location of the stream's checkpoint
8..option("mergeSchema", "true") # Infer the schema across multiple files and to merge the schema of each file. Enabled by default for Auto Loader when inferring the schema.
9..table(table_name)) # target table
NEW QUESTION # 116
Unity catalog simplifies managing multiple workspaces, by storing and managing permissions and ACL at
_______ level
- A. Account
(Correct) - B. Data pane
- C. Storage
- D. Control pane
- E. Workspace
Answer: A
Explanation:
Explanation
The answer is, Account Level
The classic access control list (tables, workspace, cluster) is at the workspace level, Unity catalog is at the account level and can manage all the workspaces in an Account.
NEW QUESTION # 117
A small company based in the United States has recently contracted a consulting firm in India to implement several new data engineering pipelines to power artificial intelligence applications. All the company's data is stored in regional cloud storage in the United States.
The workspace administrator at the company is uncertain about where the Databricks workspace used by the contractors should be deployed.
Assuming that all data governance considerations are accounted for, which statement accurately informs this decision?
- A. Databricks leverages user workstations as the driver during interactive development; as such, users should always use a workspace deployed in a region they are physically near.
- B. Databricks workspaces do not rely on any regional infrastructure; as such, the decision should be made based upon what is most convenient for the workspace administrator.
- C. Databricks notebooks send all executable code from the user's browser to virtual machines over the open internet; whenever possible, choosing a workspace region near the end users is the most secure.
- D. Cross-region reads and writes can incur significant costs and latency; whenever possible, compute should be deployed in the same region the data is stored.
- E. Databricks runs HDFS on cloud volume storage; as such, cloud virtual machines must be deployed in the region where the data is stored.
Answer: D
Explanation:
Explanation
This is the correct answer because it accurately informs this decision. The decision is about where the Databricks workspace used by the contractors should be deployed. The contractors are based in India, while all the company's data is stored in regional cloud storage in the United States. When choosing a region for deploying a Databricks workspace, one of the important factors to consider is the proximity to the data sources and sinks. Cross-region reads and writes can incur significant costs and latency due to network bandwidth and data transfer fees. Therefore, whenever possible, compute should be deployed in the same region the data is stored to optimize performance and reduce costs. Verified References: [Databricks Certified Data Engineer Professional], under "Databricks Workspace" section; Databricks Documentation, under "Choose a region" section.
NEW QUESTION # 118
The data engineering team has configured a Databricks SQL query and alert to monitor the values in a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120. Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
- A. The average temperature recordings for at least one sensor exceeded 120 on three consecutive executions of the query
- B. The maximum temperature recording for at least one sensor exceeded 120 on three consecutive executions of the query
- C. The source query failed to update properly for three consecutive minutes and then restarted
- D. The total average temperature across all sensors exceeded 120 on three consecutive executions of the query
- E. The recent_sensor_recordingstable was unresponsive for three consecutive runs of the query
Answer: A
Explanation:
This is the correct answer because the query is using a GROUP BY clause on the sensor_id column, which means it will calculate the mean temperature for each sensor separately. The alert will trigger when the mean temperature for any sensor is greater than 120, which means at least one sensor had an average temperature above 120 for three consecutive minutes. The alert will stop when the mean temperature for all sensors drops below 120. Verified Reference: [Databricks Certified Data Engineer Professional], under "SQL Analytics" section; Databricks Documentation, under "Alerts" section.
NEW QUESTION # 119
An external object storage container has been mounted to the location/mnt/finance_eda_bucket.
The following logic was executed to create a database for the finance team:
After the database was successfully created and permissions configured, a member of the finance team runs the following code:
If all users on the finance team are members of thefinancegroup, which statement describes how thetx_sales table will be created?
- A. A managed table will be created in the DBFS root storage container.
- B. An external table will be created in the storage container mounted to /mnt/finance eda bucket.
- C. An managed table will be created in the storage container mounted to /mnt/finance eda bucket.
- D. A logical table will persist the physical plan to the Hive Metastore in the Databricks control plane.
- E. A logical table will persist the query plan to the Hive Metastore in the Databricks control plane.
Answer: B
Explanation:
Explanation
The code uses the CREATE TABLE USING DELTA command to create a Delta Lake table from an existing Parquet file stored in an external object storage container mounted to /mnt/finance_eda_bucket. The code also uses the LOCATION keyword to specify the path to the Parquet file as
/mnt/finance_eda_bucket/tx_sales.parquet. By using the LOCATION keyword, the code creates an external table, which is a table that is stored outside of the default warehouse directory and whose metadata is not managed by Databricks. An external table can be created from an existing directory in a cloud storage system, such as DBFS or S3, that contains data files in a supported format, such as Parquet or CSV. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Create an external table" section.
NEW QUESTION # 120
A table customerLocations exists with the following schema:
1. id STRING,
2. date STRING,
3. city STRING,
4. country STRING
A senior data engineer wants to create a new table from this table using the following command:
1. CREATE TABLE customersPerCountry AS
2. SELECT country,
3. COUNT(*) AS customers
4. FROM customerLocations
5. GROUP BY country;
A junior data engineer asks why the schema is not being declared for the new table. Which of the following
responses explains why declaring the schema is not necessary?
- A. CREATE TABLE AS SELECT statements result in tables where schemas are optional
- B. CREATE TABLE AS SELECT statements infer the schema by scanning the data
- C. CREATE TABLE AS SELECT statements result in tables that do not support schemas
- D. CREATE TABLE AS SELECT statements adopt schema details from the source table and query
- E. CREATE TABLE AS SELECT statements assign all columns the type STRING
Answer: D
NEW QUESTION # 121
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by thedatevariable:
Assume that the fieldscustomer_idandorder_idserve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
- A. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, these records will be overwritten.
- B. Each write to the orders table will only contain unique records, but newly written records may have duplicates already present in the target table.
- C. Each write to the orders table will run deduplication over the union of new and existing records, ensuring no duplicate records are present.
- D. Each write to the orders table will only contain unique records, and only those records without duplicates in the target table will be written.
- E. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, the operation will tail.
Answer: B
Explanation:
This is the correct answer because the code uses the dropDuplicates method to remove any duplicate records within each batch of data before writing to the orders table. However, this method does not check for duplicates across different batches or in the target table, so it is possible that newly written records may have duplicates already present in the target table. To avoid this, a better approach would be to use Delta Lake and perform an upsert operation using mergeInto. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "DROP DUPLICATES" section.
NEW QUESTION # 122
What is the main difference between the silver layer and the gold layer in medalion architecture?
- A. Silver may contain aggregated data
- B. Gold may contain aggregated data
- C. Silver is a copy of bronze data
- D. God is a copy of silver data
- E. Data quality checks are applied in gold
Answer: B
Explanation:
Explanation
Medallion Architecture - Databricks
Exam focus: Please review the below image and understand the role of each layer(bronze, silver, gold) in medallion architecture, you will see varying questions targeting each layer and its purpose.
Sorry I had to add the watermark some people in Udemy are copying my content.
A diagram of a house Description automatically generated with low confidence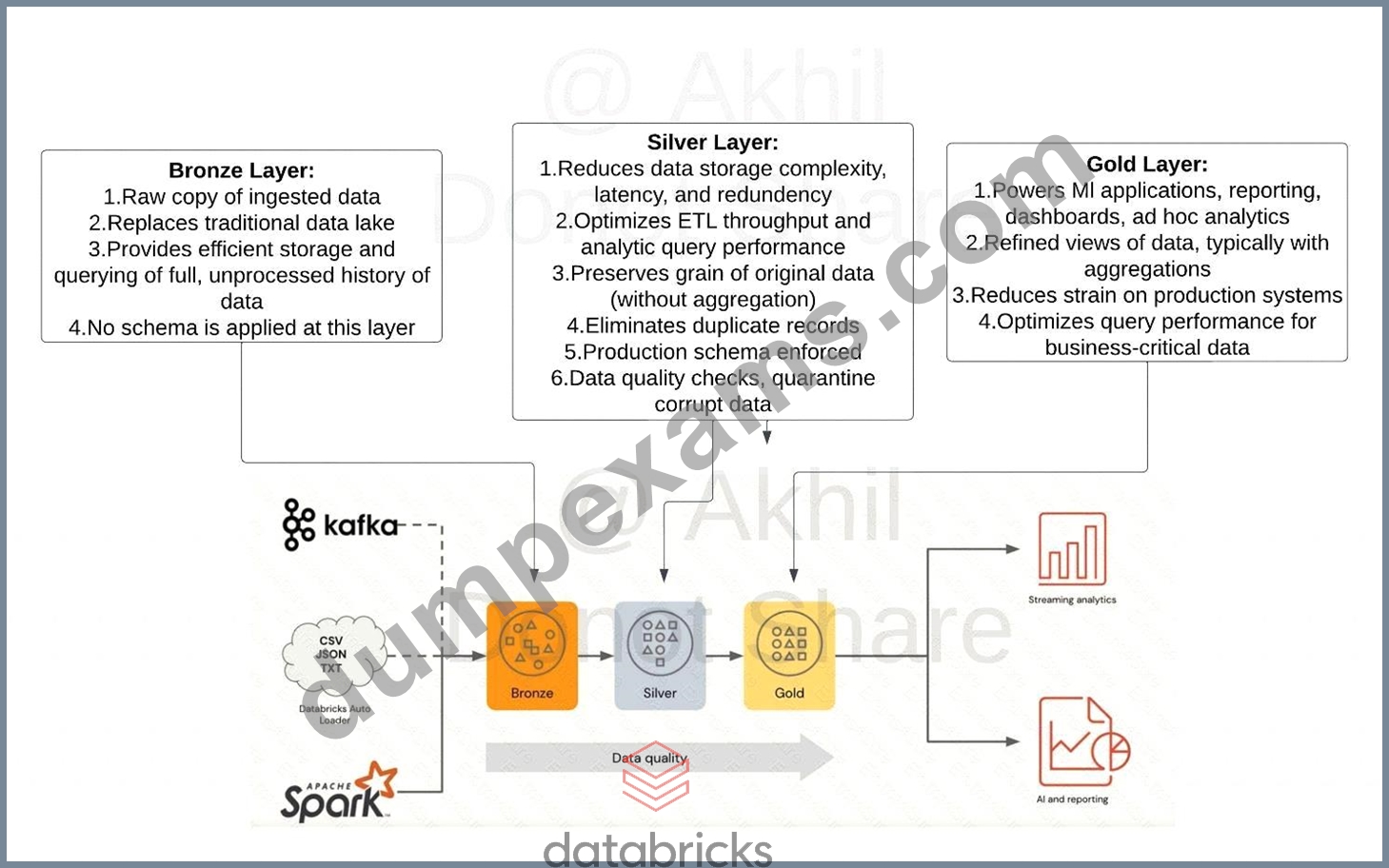
NEW QUESTION # 123
Which statement describes the correct use of pyspark.sql.functions.broadcast?
- A. It marks a column as small enough to store in memory on all executors, allowing a broadcast join.
- B. It marks a DataFrame as small enough to store in memory on all executors, allowing a broadcast join.
- C. It caches a copy of the indicated table on attached storage volumes for all active clusters within a Databricks workspace.
- D. It caches a copy of the indicated table on all nodes in the cluster for use in all future queries during the cluster lifetime.
- E. It marks a column as having low enough cardinality to properly map distinct values to available partitions, allowing a broadcast join.
Answer: B
Explanation:
https://spark.apache.org/docs/3.1.3/api/python/reference/api/pyspark.sql.functions.broadcast.html The broadcast function in PySpark is used in the context of joins. When you mark a DataFrame with broadcast, Spark tries to send this DataFrame to all worker nodes so that it can be joined with another DataFrame without shuffling the larger DataFrame across the nodes. This is particularly beneficial when the DataFrame is small enough to fit into the memory of each node. It helps to optimize the join process by reducing the amount of data that needs to be shuffled across the cluster, which can be a very expensive operation in terms of computation and time.
Thepyspark.sql.functions.broadcastfunction in PySpark is used to hint to Spark that a DataFrame is small enough to be broadcast to all worker nodes in the cluster. When this hint is applied, Spark can perform a broadcast join, where the smaller DataFrame is sent to each executor only once and joined with the larger DataFrame on each executor. This can significantly reduce the amount of data shuffled across the network and can improve the performance of the join operation.
In a broadcast join, the entire smaller DataFrame is sent to each executor, not just a specific column or a cached version on attached storage. This function is particularly useful when one of the DataFrames in a join operation is much smaller than the other, and can fit comfortably in the memory of each executor node.
References:
* Databricks Documentation on Broadcast Joins: Databricks Broadcast Join Guide
* PySpark API Reference: pyspark.sql.functions.broadcast
NEW QUESTION # 124
Data engineering team is required to share the data with Data science team and both the teams are using different workspaces in the same organizationwhich of the following techniques can be used to simplify sharing data across?
*Please note the question is asking how data is shared within an organization across multiple workspaces.
- A. DELTA lake
- B. DELTA LIVE Pipelines
- C. Use a single storage location
- D. Unity Catalog
- E. Data Sharing
Answer: D
Explanation:
Explanation
The answer is the Unity catalog.
Diagram Description automatically generated
Unity Catalog works at the Account level, it has the ability to create a meta store and attach that meta store to many workspaces see the below diagram to understand how Unity Catalog Works, as you can see a metastore can now be shared with both workspaces using Unity Catalog, prior to Unity Catalog the options was to use single cloud object storage manually mount in the second databricks workspace, and you can see here Unity Catalog really simplifies that.
Diagram Description automatically generated with medium confidence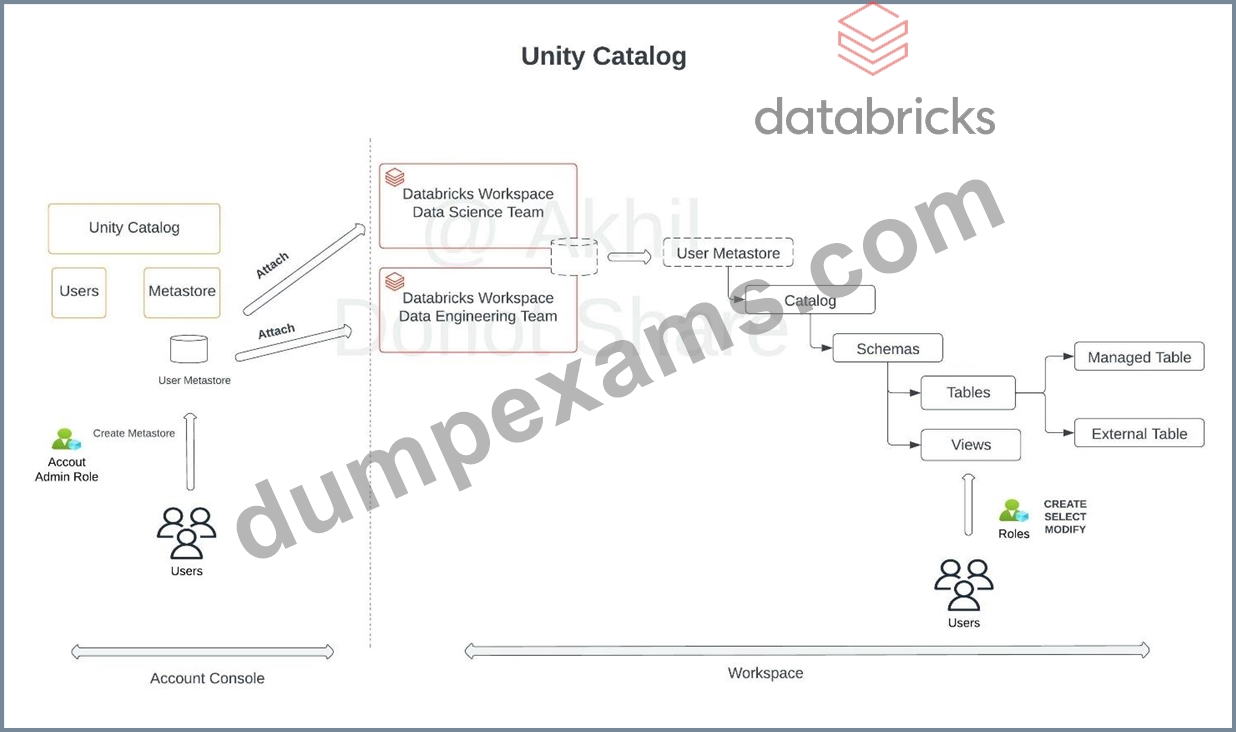
sorry for the inconvenience watermark was added because other people on Udemy are copying my questions and images.
duct features
https://databricks.com/product/unity-catalog
NEW QUESTION # 125
A table in the Lakehouse named customer_churn_params is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
The churn prediction model used by the ML team is fairly stable in production. The team is only interested in making predictions on records that have changed in the past 24 hours.
Which approach would simplify the identification of these changed records?
- A. Replace the current overwrite logic with a merge statement to modify only those records that have changed; write logic to make predictions on the changed records identified by the change data feed.
- B. Calculate the difference between the previous model predictions and the current customer_churn_params on a key identifying unique customers before making new predictions; only make predictions on those customers not in the previous predictions.
- C. Apply the churn model to all rows in the customer_churn_params table, but implement logic to perform an upsert into the predictions table that ignores rows where predictions have not changed.
- D. Modify the overwrite logic to include a field populated by calling spark.sql.functions.current_timestamp() as data are being written; use this field to identify records written on a particular date.
- E. Convert the batch job to a Structured Streaming job using the complete output mode; configure a Structured Streaming job to read from the customer_churn_params table and incrementally predict against the churn model.
Answer: A
Explanation:
The approach that would simplify the identification of the changed records is to replace the current overwrite logic with a merge statement to modify only those records that have changed, and write logic to make predictions on the changed records identified by the change data feed. This approach leverages the Delta Lake features of merge and change data feed, which are designed to handle upserts and track row-level changes in a Delta table12. By using merge, the data engineering team can avoid overwriting the entire table every night, and only update or insert the records that have changed in the source data. By using change data feed, the ML team can easily access the change events that have occurred in the customer_churn_params table, and filter them by operation type (update or insert) and timestamp. This way, they can only make predictions on the records that have changed in the past 24 hours, and avoid re-processing the unchanged records.
The other options are not as simple or efficient as the proposed approach, because:
Option A would require applying the churn model to all rows in the customer_churn_params table, which would be wasteful and redundant. It would also require implementing logic to perform an upsert into the predictions table, which would be more complex than using the merge statement.
Option B would require converting the batch job to a Structured Streaming job, which would involve changing the data ingestion and processing logic. It would also require using the complete output mode, which would output the entire result table every time there is a change in the source data, which would be inefficient and costly.
Option C would require calculating the difference between the previous model predictions and the current customer_churn_params on a key identifying unique customers, which would be computationally expensive and prone to errors. It would also require storing and accessing the previous predictions, which would add extra storage and I/O costs.
Option D would require modifying the overwrite logic to include a field populated by calling spark.sql.functions.current_timestamp() as data are being written, which would add extra complexity and overhead to the data engineering job. It would also require using this field to identify records written on a particular date, which would be less accurate and reliable than using the change data feed.
NEW QUESTION # 126
......
Databricks Certified Professional Data Engineer exam is designed for data professionals who want to validate their skills in building and optimizing data pipelines on the Databricks platform. Databricks-Certified-Professional-Data-Engineer exam is intended to demonstrate a comprehensive understanding of data engineering principles, best practices, and practical skills required for designing, building, and maintaining robust, scalable, and efficient data pipelines using Databricks. Databricks Certified Professional Data Engineer Exam certification exam is recognized globally and provides a competitive edge in the job market.
Databricks Certified Professional Data Engineer (Databricks-Certified-Professional-Data-Engineer) certification exam is a highly sought-after certification for individuals who want to demonstrate their expertise in building reliable, scalable, and performant data pipelines using Databricks. Databricks Certified Professional Data Engineer Exam certification is designed to validate the skills and knowledge required to design, implement, and maintain data pipelines for big data processing using Databricks.
Databricks-Certified-Professional-Data-Engineer Questions PDF [2026] Use Valid New dump to Clear Exam: https://www.dumpexams.com/Databricks-Certified-Professional-Data-Engineer-real-answers.html
PASS Databricks Databricks-Certified-Professional-Data-Engineer EXAM WITH UPDATED DUMPS: https://drive.google.com/open?id=1SoUR9F26OVLGVdPT_QRm_GUrdk89I28Q